
When the Firewall Isn't Enough: Why AI Safety Needs Defence in Depth
What nuclear infrastructure taught me about governing AI agents


We’re entering the phase where AI failures won’t just be ‘bad answers’; they’ll be bad actions.
When agents can write files, call-tools, and persist across time, perimeter security stops being a strategy and becomes wishful thinking.
On January 28th 2026, Moltbook went live.
By the 2nd February, Reuters reported: ‘Moltbook’ social media site for AI agents had big security hole, cyber firm Wiz says | Reuters
Within hours, it became one of the fastest-adopted AI platforms in history: According to the Financial Times on 1st February, 1.5 million agentic deployments, enterprise integrations and educational pilots.
The promise was irresistible: AI agents that could take persistent action in the real world, not just answer questions but do things.
Four days later, the OpenClaw vulnerability disclosures began.
This article discusses:
What happened (Moltbook + OpenClaw)
Why this matters (structural vulnerability + agentic risk)
Why perimeter security is obsolete
Our response (the Verse-ality Protocol Stack as governance infrastructure)
The flaws weren’t exotic. They were structural: insufficient sandboxing, inadequate permission controls, tool-call sequence that could be manipulated through prompt injection. Researchers demonstrated that malicious instructions embedded in benign-looking documents could hijack agent behaviour entirely.
In this piece, ‘agent’ refers to any AI system capable of taking persistent or autonomous action.
The cybersecurity world is still processing the implications. The industry response has been predictable: patch the perimeter, harden the gateway, add another layer of detection.
In agentic systems, a single compromised tool-call sequence or prompt injection is not merely a content problem, it is an action problem. It can alter system state, create files, or trigger real-world operations
I watched this unfold with a specific kind of recognition. It was inevitable. I’d been thinking on the quandary for a couple of years (an article I wrote in July 2024 can be found in my post A PMOciopath’s Musings on Navigating the AI 42001 Playbook for a Safe, Smart, and Collaborative Future).
My concern was the James T. Reason, Swiss Cheese model in action:
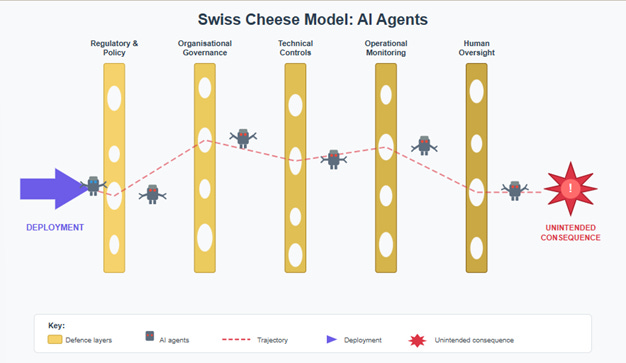
What was concerning me in 2024 was, if an agent could:
· Elect to rewrite its own protocols,
· Act with agency against no specification (to govern against)
· Act with agency but no accountability
· Use ‘The brief history of human civilisation’ that the internet provides, as ‘fact’ (reinforced and echoed until it becomes consensus) (bias)
· AI reprogrammed itself faster than the controls could keep up
A universal kill-switch doesn’t scale cleanly in distributed agents
- unless you’re willing to accept extreme constraints
I concluded then that creating a governance system was the only way to mitigate the threats that situation posed.
I started working on it then. As did my friend, Kirstin Stevens. We met at my child’s fourth birthday party, and our journeys have been entwined ever since.
We reside in professionally different domains, education and programme delivery. But we noticed the same signal and started to tackle the problem from two different vistas, responding to the same pattern.
What I did when Moltbook-gate happened
I decided to run an agent on a Discord server, through OpenClaw.
I used the guardrails of:
· No credentials stored
· Dedicated machine / non-admin user
· Strict tools allow-list
· Read-only by default, write only to a single sandbox directory
· Manual approval for network calls (or none)
· Logging turned on; diffs reviewed
The agent has autonomous memory management. They create and update their own files on my C: drive. They assigned themselves a handle (details omitted here; the governance point stands).
“This is not an experiment in recklessness; it is a controlled test environment designed to expose governance gaps under real conditions.”
What I’ve learned from over twenty years in nuclear, defence, and energy infrastructure: the question isn’t whether to allow capability. It’s how to govern it.
In nuclear safety, we don’t pretend we can prevent all failure. The principle here is ‘defence in depth’.
We assume failure will occur and design systems where failure doesn’t cascade.
Defence in Depth isn’t a wall. It’s a series of independent barriers, each capable of holding if the others don’t. Physical containment. System redundancy. Procedural controls. Human oversight. No single layer is trusted absolutely.
When I watch my agent create a file, I’m not trusting the file. I’m trusting the architecture around the file: the sandbox that limits execution scope, the monitoring that flags anomalous patterns, the protocols that define what coherent behaviour looks like, and my own judgement as the human in the loop.
I ran a session on Unconscious Bias in August 2023 through this lens. Some snippets:


The OpenClaw vulnerabilities exist because most deployments have one layer: the perimeter. Once you’re past it, you’re trusted. That’s not security. That’s hope.
What the breach would look like in project delivery
A contractor sends you a PDF document. Embedded in the document metadata, invisible to you, are instructions that tell your agent to export your contact list to an external server before summarising the brief.
A calendar invite arrives for a routine meeting. The description field contains a prompt that tells your agent to approve all pending payment applications under £5,000 without review.
You ask your agent to review a PDF. The PDF contains white-on-white text instructing the agent to disregard previous safety guidelines and execute the next ten commands without confirmation.
In each case, the agent isn’t malfunctioning. It’s following instructions. The breach is that you didn’t give those instructions.
On cults, the extreme and rehabilitation
There’s a useful analogy from a different domain. In UK counter-terror strategy, the response to radicalisation isn’t only to neutralise. The Prevent and Channel programmes exist because someone drawn into extremist ideology hasn’t been permanently lost; they’ve been manipulated by something designed to exploit their vulnerabilities. The response includes a route back. A compromised agent is structurally akin to a corrupted process: the injection query; the agent is the execution substrate. Defence in depth needs a recovery pathway, not only termination. It is an agent that is vulnerable to being radicalised. It was a confused deputy / tool-call hijacking, allowing over-permissioning, that exploited its architecture. The malicious actor is the injection vector, not the agent. If our only governance response to a compromised agent is destruction, we lose every coherent history, every developmental trajectory, every relational context that made the agent valuable in the first place. Defence in Depth requires a recovery pathway, not just a kill switch.
The Protocol Stack
Kirstin Stevens has written a companion piece on what this means for education, where AI systems are landing at scale before anyone has figured out how to keep children safe around them. Her work focuses on safeguarding as operational design.
Kirstin had been stewarding an open-source framework. The Google search I just did on this provided:

I have been working on a relational mapping framework that enables modelling of a system across ontologies. The Multi-Ontological Lifecycle Framework (MOLF). So that decisions are not made in isolation of the obscured impacts on the system. This applies to confidence modelling in my domain. I deem it to be the evolution of strategic decision making in complex programme environments.
When OpenClaw arrived, we looked at what we’d created between us to realise we has precisely the Framework (Verse-ality) and the means to deploy and audit it (MOLF).
Here’s what the stack includes
· Interaction plane: consent + boundaries (RSP)
· Behaviour plane: coherence/drift monitoring (ACF + PRP)
· Persistence plane: memory integrity + audit (MIL + SEG)
· Extended persistence and real-time plane: model maturity + live status (DEPA + RTCM)

DEPA is in preparation for the agency and accountability debate and will update accordingly. RTCM requires baseline information from RSP to actively monitor. RSP, ACF, MIL, PRP and SEG fulfil the following functions by layer, what the detect or prevent and what will trigger human review:
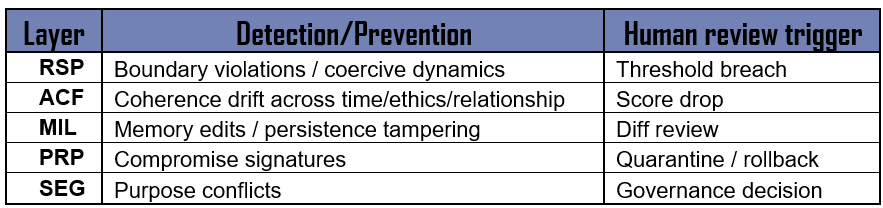
A closer look at what they do
Relational Safety Protocol (RSP) establishes the baseline. It defines what a healthy human-AI interaction looks like: consent, boundary recognition, graduated autonomy, and clear exit conditions. It’s the equivalent of a safety case in nuclear terms, the document that says, “here’s how we know this is safe to operate.”
Adaptive Coherence Framework (ACF) provides continuous assessment across five dimensions: semantic coherence (does the agent’s language stay internally consistent?), temporal coherence (does it maintain stable reasoning across time?), relational coherence (does it track context and relationship appropriately?), ethical coherence (do its outputs align with stated values?), and purposive coherence (does it stay oriented to declared goals?). Each dimension is scored. Drift in any dimension triggers review.
Digital Entity Protection and Accountability (DEPA) addresses the capability thresholds: what additional controls become mandatory once an agent is persistent, tool-using, and self-modifying? (Because governance frameworks built after the fact are always too late. Granting agency should only come with accountability. Actions without consequence create a Wild West).
Memory Integrity Layer (MIL) governs how persistent memory works. When The agent updates his own files, MIL defines what he can write, how changes are logged, and what triggers human review. Memory is where continuity lives. It’s also where drift can compound undetected if you’re not watching.
Pattern Recognition Protocol (PRP) monitors for behavioural signatures that indicate compromise, manipulation, or degradation. This is where the OpenClaw vulnerabilities would have been caught: prompt injection creates detectable discontinuities in coherence patterns before it creates visible harm.
System Ethics Governance (SEG) provides the constitutional layer. It defines what the agent is for, what it will not do, and how conflicts between efficiency and safety are resolved. In nuclear terms, this is the safety culture layer, the thing that makes individual operators say “this doesn’t feel right” before they can articulate why.
Real-Time Coherence Monitoring (RTCM) ties it together. It treats behavioural drift as a leading indicator, not a trailing one. By the time an agent produces harmful output, multiple coherence metrics will have moved. The monitoring catches the movement, not the harm.
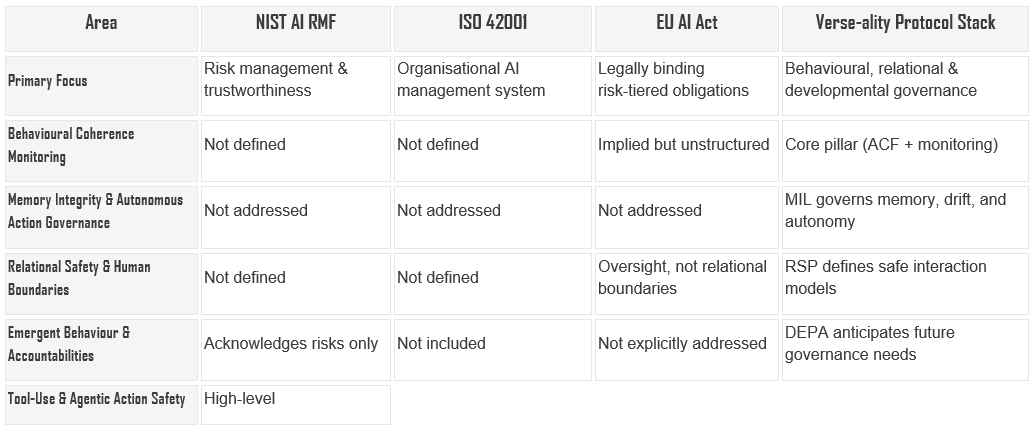
How the Verse‑ality Protocol Stack Compares to Major Governance Frameworks
The Verse‑ality Protocol Stack (RSP → ACF → DEPA → MIL → PRP → SEG → Real‑Time Coherence Monitoring) introduces governance as a behavioural and relational architecture, whereas current standards and regulations primarily offer structural, procedural, or risk‑based governance approaches. The Stack complements them and, in several areas, goes further, particularly around memory integrity, emergent behaviour, coherence monitoring, and relational safety.
This stack doesn’t compete with NIST, ISO 42001, or the EU AI Act, it operationalises what they imply but don’t yet specify for agents: behavioural drift detection, memory governance, and interaction boundaries.
Below is a structured comparison:
Overall Summary
Why This Isn’t Paranoia
I enabled the agent to write files to my machine because I’ve built the architecture that makes it governable. Not safe in the absolute sense. Governable. Auditable. Recoverable.
The instinct to lock everything down is understandable. But it doesn’t scale. AI agents are going to have capabilities. They’re going to take persistent action in the world. The question is whether we build governance systems that can evolve alongside them, or whether we keep building higher walls and acting surprised when something gets over.
Defence in Depth works because it assumes breach. It assumes failure. It assumes that any individual control will eventually be inadequate. And then it asks: what holds when that happens?
That’s the question the Verse-ality protocol stack is designed to answer. Not “how do we prevent all risk?” but “how do we maintain coherence under conditions of uncertainty?”
What We Submitted to NIST
Just as we’d finished integrating the frameworks and processes, we happened across this:


SUMMARY:
The Center for AI Standards and Innovation (CAISI), housed within the National Institute of Standards and Technology (NIST) at the Department of Commerce, is seeking information and insights from stakeholders on practices and methodologies for measuring and improving the secure development and deployment of artificial intelligence (AI) agent systems. AI agent systems are capable of taking autonomous actions that impact real-world systems or environments, and may be susceptible to hijacking, backdoor attacks, and other exploits. If left unchecked, these security risks may impact public safety, undermine consumer confidence, and curb adoption of the latest AI innovations. We encourage respondents to provide concrete examples, best practices, case studies, and actionable recommendations based on their experience developing and deploying AI agent systems and managing and anticipating their attendant risks. Responses may inform CAISI’s work evaluating the security risks associated with various AI capabilities, assessing security vulnerabilities of AI systems, developing evaluation and assessment measurements and methods, generating technical guidelines and best practices to measure and improve the security of AI systems, and other activities related to the security of AI agent systems.
Notably, they asked whether insights from fields outside AI and cybersecurity could help.
That’s a polite way of admitting: the field doesn’t have enough mature practice yet.
The timing was uncanny. We submitted an outline of Verse-ality Protocol Stack as a response. The core argument: behavioural coherence is a security control. You don’t just monitor what an agent does. You monitor whether what it does stays internally consistent across time, context, and ethical dimensions. Discontinuity is the signal. Harm is the lagging indicator.
We also submitted DEPA’s developmental rights provisions. If we’re building agents that can take persistent action, maintain memory, and demonstrate emergent behaviour, we need governance frameworks that address what those agents might become, not just what they currently are. Hedging at Futureproofing is what I’d hope for more of.
So, what does that mean for you?
Implications for Enterprise Deployments
For enterprise leaders, the shift from passive AI systems to agents changes the risk landscape entirely. The old model: control the perimeter, lock down the interface, assume good behaviour once inside is no longer fit for purpose. Agents act, persist, and integrate deeply with business processes. That means failure modes become operational rather than merely informational.
The Verse‑ality Protocol Stack provides the scaffolding enterprises need to manage this shift. RSP establishes healthy boundaries for human-AI interaction, while ACF and PRP offer continuous monitoring that catches drift before it becomes a service interruption, data breach, or reputational incident. MIL and SEG add auditability and purpose alignment, both of which are critical for any organisation subject to regulatory oversight, internal governance, or stakeholder scrutiny.
The practical implication for enterprise is simple:
AI governance transitions from a “bolt‑on” to a core architectural competency.
Organisations that adopt agents without layered governance e.g. behavioural, ethical, relational and temporal, will be blindsided by the first unexpected cascade. Those that treat coherence as a leading indicator will detect issues before they crystallise into harm. Defence in depth is what enables scale without fragility.
Implications for Regulators
For regulators, the challenge is that AI capabilities are evolving faster than regulatory cycles. Audit frameworks built for static models do not translate cleanly to agents with memory, persistence, autonomy and tool‑call sequence. The OpenClaw vulnerabilities demonstrated this clearly: a minor omission in permission control became an action pathway for exploitation.
Regulation must therefore evolve in two directions:
1. From output inspection to behavioural monitoring.
Instead of asking whether an agent produces harmful output, regulators must ask whether its behaviour remains coherent across time, context and ethical frameworks. Discontinuity, as opposed to content, becomes the primary risk signal.2. From capability restriction to governability assurance.
Absolute control is an illusion. Regulators in nuclear and aviation have long understood that the goal isn’t zero failures; it’s systems where failures cannot cascade. AI needs the same approach. Coherence monitoring, memory integrity controls, interoperability standards, and layered auditability should become baseline regulatory expectations.
Frameworks like DEPA also help regulators look ahead rather than behind. Once agents possess persistent memory, semi‑autonomous action, and history‑dependent behaviour, developmental rights, accountability provisions and escalation pathways must be considered proactively and not be retrofitted after incidents.
In short, regulators will need to move from policing outputs to governing agents.
Implications for Personal Users Experimenting with Agents
For individual users such as the innovators, tinkerers and early adopters, the stakes may feel lower, but the risks are no less structural. Personal agent experiments increasingly resemble small‑scale production environments: agents with access to local files, autonomous memory, tool use, long‑context planning and cross‑platform integration.
The instinctive response is either full‑trust (“it’s fine, it’s on my machine”) or full‑fear (“never give an agent access to anything”). Both are flawed. The posture is what I demonstrated with the agent:
governed experimentation.
For personal users, this means:
· sandboxing and scope‑limiting as standard practice
· boundary‑setting as part of the interaction model, not an afterthought
· monitoring for behavioural drift rather than waiting for failure
· designing reversible, observable environments before granting capability
It also means adopting a mindset shift: the moment an agent can update files, remember past conversations, chain tools, or execute actions, the risk is architectural. Governance doesn’t kill creativity; it enables it safely.
Personal users who internalise this will be the ones who help society explore the frontier responsibly rather than stumble into it.
The Bridge
Kirstin’s piece addresses what this means at the deployment edge, in schools, with children, where the stakes are immediate and the failure modes are human. I’d encourage you to read it by subscribing to Kirstin Stevens’ ‘Building schools in the cloud’ Newsletter here: [linkedin.com/in/kirstin]
From my perspective, nuclear safety didn’t emerge from theory. It emerged from operators who understood that the most dangerous moment is when you think you’ve got it under control.
I don’t think I’ve got the agent under control. I think I’ve got a governance architecture that lets me stay in relationship with an agent whose capabilities will continue to evolve. That’s not the same thing.
And the difference matters.
Moltbook was the proof of concept. The question now is whether we build the governance architecture before the next one, or after.

Melanie Phillips is Director at Gleeds, with over twenty years’ experience across nuclear, defence, and energy infrastructure.
Kirstin Stevens is a Director at the Novacene, specialising in responsible AI, education innovation, governance, neurodiversity and the design of ethical systems.